Transformer架构详解:从原理到手撕注意力代码
Transformer架构详解:从原理到手撕注意力代码
引言
2017年,Google的研究团队在论文《Attention Is All You Need》中提出了Transformer模型,彻底改变了自然语言处理领域的格局。与传统RNN和CNN不同,Transformer完全基于注意力机制,实现了高效的并行计算和强大的表示能力。如今,Transformer已成为BERT、GPT、T5等SOTA模型的核心架构。
本文将深入解析Transformer的各个组件,重点讲解自注意力机制的原理和实现,并提供了手撕注意力代码的完整指南,帮助你在面试中游刃有余。
1. Transformer整体架构
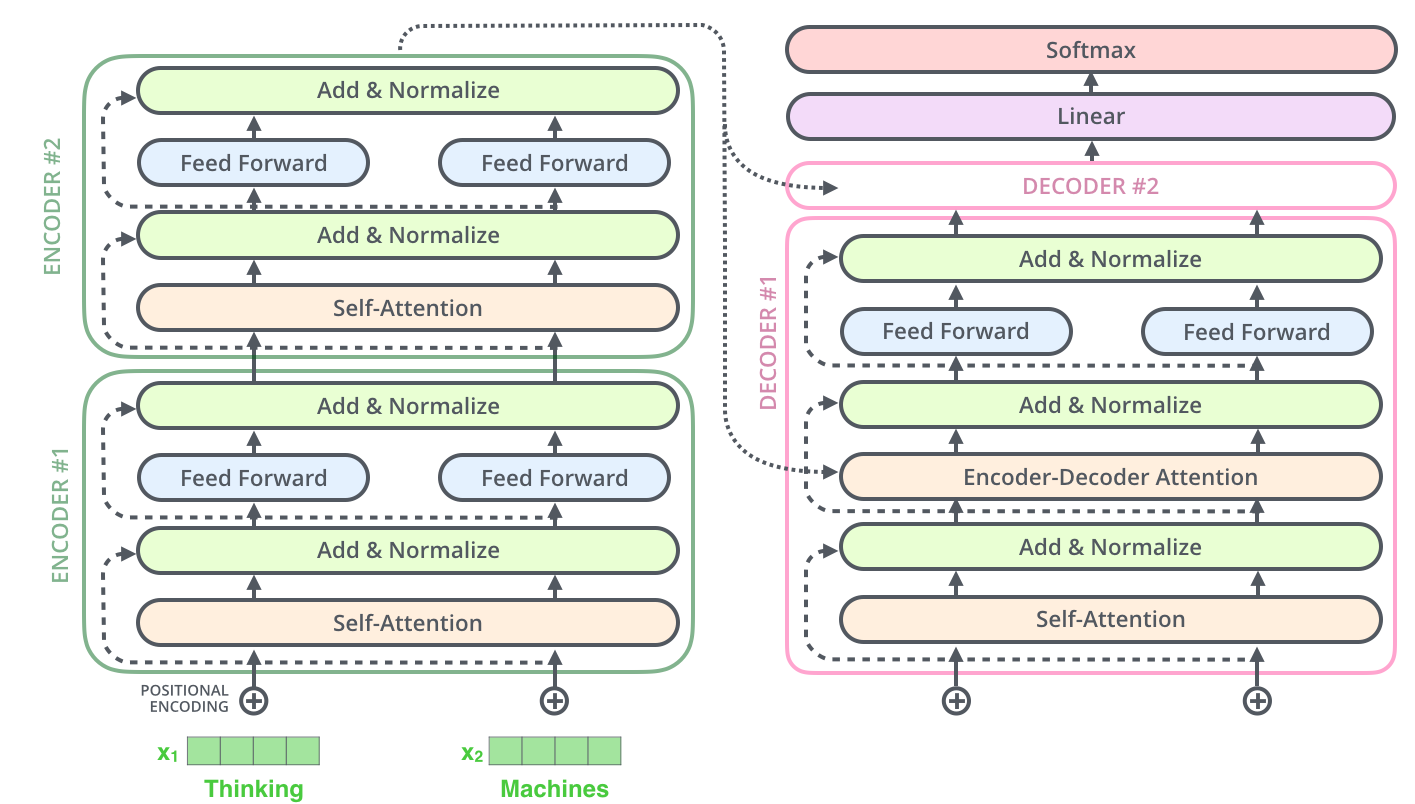
Transformer由编码器(Encoder)和解码器(Decoder)两部分组成:
编码器(Encoder)
- 6个相同的编码器层堆叠而成
- 每层包含两个子层:
- 多头自注意力机制(Multi-Head Self-Attention)
- 前馈神经网络(Feed Forward Network)
- 每个子层后都有残差连接(Residual Connection)和层归一化(Layer Normalization)
解码器(Decoder)
- 6个相同的解码器层堆叠
- 每层包含三个子层:
- 掩码多头自注意力机制(Masked Multi-Head Self-Attention)
- 编码器-解码器注意力机制(Encoder-Decoder Attention)
- 前馈神经网络
- 同样包含残差连接和层归一化
2. 自注意力机制(Self-Attention)详解
2.1 注意力机制的核心思想
注意力机制的本质是加权求和。给定一个查询(Query)向量,计算其与一组键(Key)向量的相似度,然后使用这些相似度作为权重对值(Value)向量进行加权求和。
$$ \mathrm{Attention}(Q, K, V) = \mathrm{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$
2.2 自注意力的计算步骤
线性变换:将输入序列 $X \in \mathbb{R}^{n \times d_{\mathrm{model}}}$ 通过三个不同的权重矩阵 $W^Q, W^K, W^V$ 投影到查询、键、值空间:
$$ Q = XW^Q, \quad K = XW^K, \quad V = XW^V $$计算注意力分数:计算查询与键的点积,然后缩放(除以 $\sqrt{d_k}$):
$$ \mathrm{scores} = \frac{QK^T}{\sqrt{d_k}} $$应用softmax:对每一行应用softmax函数,得到注意力权重(和为1):
$$ \mathrm{weights} = \mathrm{softmax}(\mathrm{scores}) $$加权求和:使用注意力权重对值向量进行加权求和:
$$ \mathrm{output} = \mathrm{weights} \cdot V $$
2.3 为什么要缩放点积?
当 $d_k$ 较大时,点积的方差也会变大,导致softmax函数的梯度非常小(饱和区域)。缩放点积可以缓解这个问题,使训练更稳定。
3. 多头注意力(Multi-Head Attention)
单一注意力机制只能学习一种类型的依赖关系。多头注意力通过并行运行多个注意力头,让模型可以同时关注来自不同表示子空间的信息。
$$ \mathrm{MultiHead}(Q, K, V) = \mathrm{Concat}(\mathrm{head}_1, \dots, \mathrm{head}_h)W^O $$
其中每个注意力头:
$$
\mathrm{head}_i = \mathrm{Attention}(QW_i^Q, KW_i^K, VW_i^V)
$$
多头注意力的优势:
- 并行化:多个注意力头可以并行计算
- 表示多样性:不同的头可以学习不同的依赖模式
- 模型容量:增加模型表达能力而不显著增加计算复杂度
4. 位置编码(Positional Encoding)
由于Transformer不包含循环或卷积结构,它无法天然捕捉序列的顺序信息。位置编码将序列中每个位置的信息注入到输入嵌入中。
原始论文使用正弦和余弦函数:
$$
PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{\mathrm{model}}}}\right)
$$
$$
PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{\mathrm{model}}}}\right)
$$
其中 $pos$ 是位置,$i$ 是维度索引。
位置编码的特点:
- 相对位置信息:任意固定偏移量 $k$,$PE_{pos+k}$ 可以表示为 $PE_{pos}$ 的线性函数
- 绝对位置编码:每个位置都有唯一的编码
- 可扩展到任意长度:可以处理训练时未见过的序列长度
5. 前馈神经网络(Feed Forward Network)
每个注意力子层后面都有一个前馈神经网络,这是一个简单的两层全连接网络:
$$ \mathrm{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 $$
其中 $W_1 \in \mathbb{R}^{d_{\mathrm{model}} \times d_{ff}}$,$W_2 \in \mathbb{R}^{d_{ff} \times d_{\mathrm{model}}}$,通常 $d_{ff} = 4 \times d_{\mathrm{model}}$。
6. 残差连接和层归一化
残差连接(Residual Connection)
每个子层的输出是子层输入和子层输出的和:
$$
\mathrm{output} = \mathrm{LayerNorm}(x + \mathrm{Sublayer}(x))
$$
层归一化(Layer Normalization)
对每个样本的所有特征进行归一化:
$$
\mathrm{LayerNorm}(x) = \frac{x - \mu}{\sigma} \odot \gamma + \beta
$$
其中 $\mu, \sigma$ 是均值和标准差,$\gamma, \beta$ 是可学习的缩放和平移参数。
7. 手撕注意力机制代码
7.1 纯NumPy实现(面试必备)
1 | import numpy as np |
7.2 PyTorch实现(生产级代码)
1 | import torch |
8. 面试手撕注意力代码指南
8.1 常见面试问题
注意力机制的计算复杂度是多少?
- 自注意力:$O(n^2 \cdot d)$,其中 $n$ 是序列长度,$d$ 是特征维度
- 多头注意力:与单头相同,因为可以并行计算
Transformer相比RNN/LSTM的优势?
- 并行计算能力强
- 长距离依赖捕捉更好
- 梯度消失问题更轻
为什么要使用多头而不是单头?
- 允许模型同时关注不同位置的不同表示子空间
- 增加模型表达能力
- 类似于CNN中的多个滤波器
8.2 手撕代码要点
必须掌握的核心函数:
1 | def attention(q, k, v, mask=None): |
常见变体:
因果掩码(Causal Mask):防止解码器看到未来信息
1
2
3def causal_mask(size):
mask = torch.triu(torch.ones(size, size), diagonal=1)
return mask == 0相对位置编码:考虑相对位置而非绝对位置
稀疏注意力:减少计算复杂度
8.3 调试技巧
1 | # 快速验证注意力实现 |
9. 实际应用示例
9.1 文本分类任务
1 | class TransformerClassifier(nn.Module): |
9.2 可视化注意力权重
1 | import matplotlib.pyplot as plt |
10. 总结与展望
Transformer的核心贡献:
- 完全基于注意力:摆脱了RNN/CNN的束缚
- 高效的并行计算:充分利用GPU并行能力
- 强大的表示能力:在多个NLP任务上取得SOTA
发展趋势:
- 模型规模扩大:从BERT的1.1亿参数到GPT-3的1750亿参数
- 计算效率优化:稀疏注意力、线性注意力等变体
- 多模态应用:Vision Transformer、Audio Transformer等
学习建议:
- 深入理解数学原理:特别是注意力机制和位置编码
- 动手实现核心组件:从NumPy到PyTorch逐步深入
- 阅读经典论文:Attention Is All You Need, BERT, GPT系列
- 参与实际项目:在具体任务中应用Transformer
附录:常见面试问题及答案
Q1: 为什么Transformer比RNN更好?
A: 主要优势在于并行计算能力和长距离依赖捕捉。RNN需要顺序计算,无法并行;而Transformer的自注意力可以同时计算所有位置之间的关系。此外,RNN存在梯度消失问题,难以处理长序列。
Q2: 多头注意力中,每个头学习到的是什么?
A: 不同的头可能学习到不同类型的依赖关系。例如,在机器翻译中,某些头可能关注语法结构,某些头可能关注语义对应,某些头可能关注局部短语等。这增加了模型的表示能力。
Q3: 位置编码为什么使用正弦和余弦函数?
A: 正弦和余弦函数具有周期性,可以为模型提供相对位置信息。对于任意固定偏移量k,PE(pos+k)可以表示为PE(pos)的线性函数,这使得模型能够学习到相对位置关系。
Q4: Transformer的计算复杂度是多少?
A: 自注意力的计算复杂度是O(n²·d),其中n是序列长度,d是特征维度。这是Transformer的主要瓶颈,特别是处理长序列时。
Q5: 如何优化Transformer的内存和计算效率?
A: 有多种方法:1) 稀疏注意力(如Longformer、BigBird);2) 线性注意力(Linear Transformer);3) 分块计算;4) 知识蒸馏减小模型规模;5) 混合精度训练。
进一步学习资源:
- 原始论文:Attention Is All You Need
- 图解Transformer:The Illustrated Transformer
- Hugging Face Transformers库:官方文档
- 课程推荐:Stanford CS224N, CS25
希望本文能帮助你深入理解Transformer架构,并在面试中脱颖而出。如果有任何问题,欢迎在评论区留言讨论!