CLIP论文深度解析:视觉-语言预训练的范式转移
CLIP论文深度解析:视觉-语言预训练的范式转移
引言
2021年,OpenAI发布了论文《Learning Transferable Visual Models From Natural Language Supervision》,提出了CLIP(Contrastive Language-Image Pre-training)模型。这项工作在多模态学习领域引起了革命性的变化,彻底改变了视觉模型的训练范式。
核心问题:传统的视觉模型(如ResNet、ViT)依赖于固定的、人工标注的标签集进行监督学习。这种范式存在两个根本性限制:
- 有限的语义理解:模型学习的是”这张图对应编号385”,而不知道385代表”火烈鸟”及其相关语义
- 泛化能力受限:模型只能识别训练时见过的类别,无法处理新概念或开放域任务
CLIP的核心创新:直接利用互联网上现成的4亿对”图像-文本”数据进行训练,通过对比学习将视觉特征与自然语言语义对齐。这使得模型:
- 不再受限于预定义的分类列表
- 获得了理解任意文本描述的能力
- 实现了真正的零样本迁移
革命性意义:CLIP标志着视觉模型从”离散标签监督”向”自然语言监督”的范式转移,为开放域视觉理解奠定了基础。
核心范式转移:从”离散标签”到”自然语言监督”
传统监督学习的局限性
在CLIP之前,几乎所有视觉模型都遵循相同的范式:
- 固定标签集:如ImageNet的1000类、CIFAR的10/100类
- 人工标注:需要大量人力进行精确标注
- 有限语义:模型学习的是离散的one-hot向量,缺乏丰富的语义信息
- 封闭世界假设:模型只能识别训练时见过的类别
自然语言监督的革命
CLIP完全颠覆了这一范式:
- 数据来源:直接从互联网爬取4亿对图文数据,无需人工标注
- 监督信号:使用完整的自然语言句子作为监督信号
- 语义丰富性:文本描述包含丰富的语义信息、属性和关系
- 开放世界:理论上可以理解任何能用自然语言描述的概念
实际对比:ImageNet分类 vs CLIP理解
| 方面 | 传统模型 | CLIP |
|---|---|---|
| 监督信号 | “类别385” | “一只火烈鸟站在水里” |
| 语义理解 | 知道是”类别385” | 知道是”火烈鸟”、”站着”、”水里” |
| 泛化能力 | 只能识别1000类 | 可以理解任意描述 |
| 数据获取 | 需要人工标注 | 自动从互联网获取 |
这种范式转移的核心价值在于:让模型从”识别”升级到”理解”。
核心架构设计:双塔结构与对比学习
CLIP的成功不仅在于范式创新,更在于其精巧的架构设计。整个模型采用双塔结构(Two-tower Architecture),包含独立的图像编码器和文本编码器。
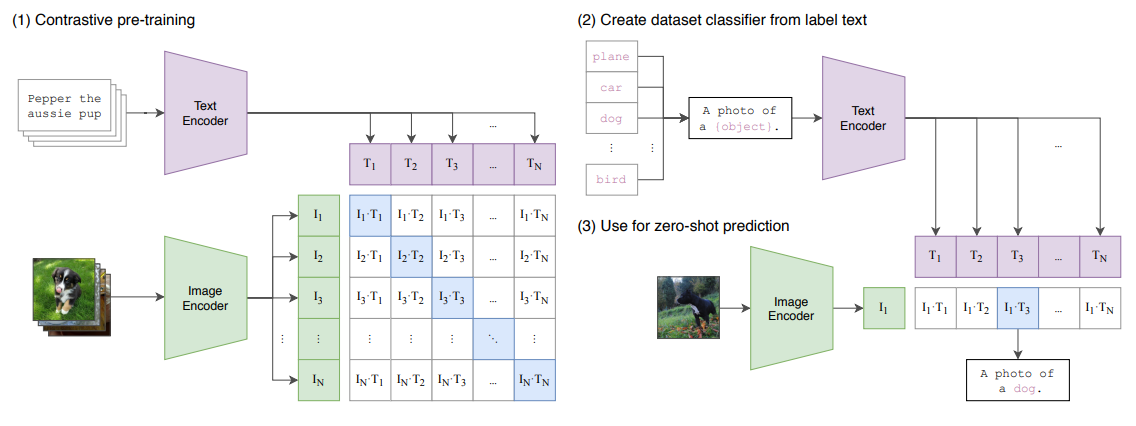
图1:CLIP原始架构图(来自论文)
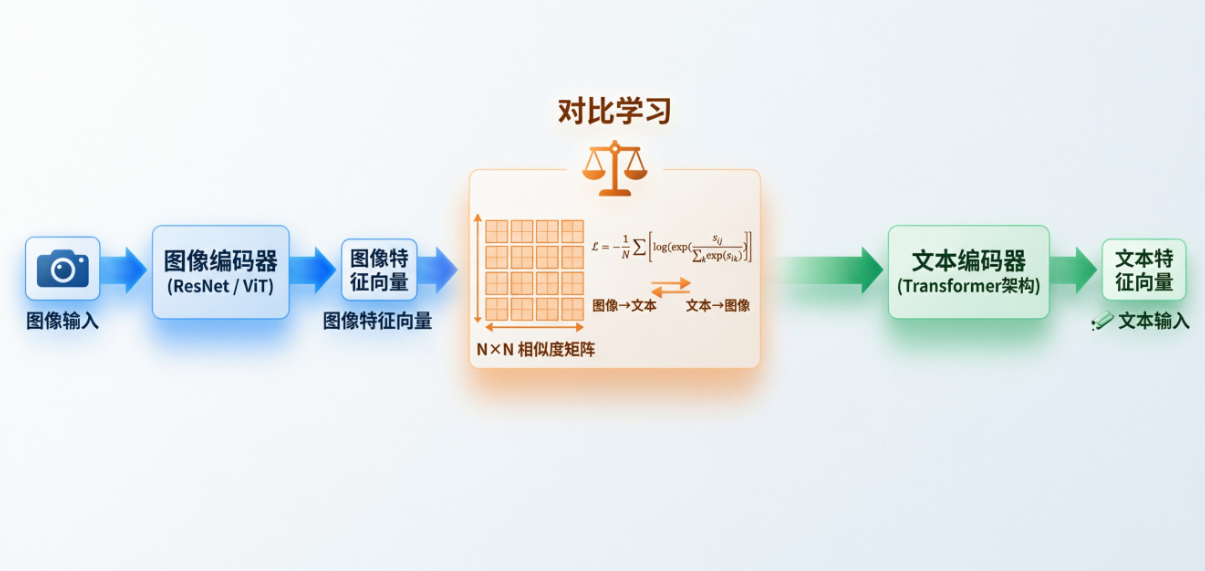
图2:CLIP简化架构图(核心组件示意)
图像编码器
CLIP支持两种主干网络:
- ResNet变体:包括ResNet-50、ResNet-101等,经过修改适配
- Vision Transformer(ViT):包括ViT-B/32、ViT-B/16、ViT-L/14等
两种编码器都将输入图像转换为固定维度的特征向量:
$$
f_{\text{image}}: \mathbb{R}^{H \times W \times 3} \rightarrow \mathbb{R}^d
$$
文本编码器
文本编码器基于标准的Transformer架构:
- 输入处理:文本通过BPE分词,添加[CLS]和[SEP]标记
- 位置编码:添加可学习的位置嵌入
- Transformer编码:12层Transformer块,隐藏维度512
- 特征提取:使用[CLS]标记的表示作为文本特征
$$ f_{\text{text}}: \text{Token序列} \rightarrow \mathbb{R}^d $$
双塔结构的关键设计
- 参数独立:图像编码器和文本编码器参数不共享
- 特征维度对齐:两者输出相同维度$d$的特征向量
- 并行计算:可以同时处理图像和文本批次
对比学习机制
这是CLIP最核心的训练机制。在一个包含$N$对图文的批次中:
- 计算所有图像特征$I_i$和文本特征$T_j$之间的余弦相似度
- 构建$N \times N$的相似度矩阵$S$,其中$s_{ij} = \text{cosine_similarity}(I_i, T_j)$
- 目标是最大化对角线上的相似度(正确配对),最小化非对角线上的相似度(错误配对)
余弦相似度计算:
$$
\text{cosine\_similarity}(u, v) = \frac{u \cdot v}{\|u\| \|v\|}
$$
对比损失函数(InfoNCE损失):
$$
\begin{aligned}
\mathcal{L}\_{\text{contrastive}} = &-\frac{1}{N} \sum_{i=1}^N \Bigg[ \log \frac{\exp(s_{ii}/\tau)}{\sum_{j=1}^N \exp(s_{ij}/\tau)} \\
&+ \log \frac{\exp(s_{ii}/\tau)}{\sum_{j=1}^N \exp(s_{ji}/\tau)} \Bigg]
\end{aligned}
$$
其中$\tau$是温度参数,控制相似度分布的尖锐程度。
温度参数$\tau$的作用
- 小$\tau$:相似度分布更尖锐,模型更关注困难负样本
- 大$\tau$:相似度分布更平滑,训练更稳定
- 优化效果:合适的$\tau$能显著提升模型性能
批次构建策略
CLIP采用对称的对比损失:
- 图像到文本:每张图像要与$N$个文本描述计算相似度
- 文本到图像:每个文本描述要与$N$张图像计算相似度
- 对称优化:同时优化两个方向的对比损失
这种设计确保了双向语义对齐的有效性。
训练算法:大规模对比学习实现
数据预处理流程
- 数据收集:从互联网爬取4亿对图文数据
- 数据清洗:过滤低质量、不相关、不当内容
- 图像处理:随机裁剪、水平翻转、颜色抖动等增强
- 文本处理:最大长度77个token,BPE分词
批次构建与内存优化
训练大规模对比学习面临的主要挑战是内存消耗:
- 一个批次包含$N$对图文,需要存储$N \times N$的相似度矩阵
- 解决方案:使用梯度检查点、混合精度训练、模型并行
训练超参数配置
| 参数 | 值 | 说明 |
|---|---|---|
| 批次大小 | 32,768 | 使用多个GPU累积梯度 |
| 学习率 | 5e-4 | 余弦退火调度 |
| 优化器 | AdamW | $\beta_1=0.9$, $\beta_2=0.98$, $\epsilon=1e-6$ |
| 权重衰减 | 0.2 | 防止过拟合 |
| 温度参数$\tau$ | 0.07 | 可学习参数,初始化为0.07 |
| 训练步数 | 250,000 | 约2周训练时间 |
硬件要求与训练时间
- 硬件:592个V100 GPU(256个用于ResNet,336个用于ViT)
- 训练时间:约2周
- 内存消耗:单个模型约6GB GPU内存
- 总计算量:约10^19 FLOPs
收敛性分析
CLIP的训练表现出良好的收敛性:
- 损失曲线:对比损失稳定下降,没有明显震荡
- 梯度范数:梯度保持稳定,没有梯度爆炸/消失
- 特征质量:可视化显示特征空间逐渐形成语义结构
关键训练技巧
- 梯度累积:解决大批次内存问题
- 混合精度训练:FP16计算,FP32主权重
- 学习率预热:前2000步线性预热
- 权重衰减分离:对权重和偏置使用不同的衰减系数
- 标签平滑:轻微标签平滑(0.1)防止过拟合
零样本迁移:Prompt Engineering的力量
这是CLIP论文最惊艳的部分:模型在完全没有见过某个数据集的训练集时,就能直接进行分类。这种能力来源于自然语言监督的本质优势。
Prompt Engineering(提示词工程)
为了将分类任务适配到CLIP的框架,需要将类别标签转换为自然语言描述:
基本模板:
1 | templates = [ |
数学表达:
给定类别集合$\mathcal{Y} = {y_1, y_2, \dots, y_K}$,对于每个类别$y_k$,生成多个提示文本:
$$
T(y_k) = \{\text{template}_1(y_k), \text{template}_2(y_k), \dots, \text{template}_M(y_k)\}
$$
推理过程
- 图像编码:输入图像通过图像编码器得到特征向量$I$
- 文本编码:所有类别的提示文本通过文本编码器得到特征矩阵$T$
- 相似度计算:计算$I$与$T$中每个文本特征的余弦相似度
- 类别决策:选择相似度最高的类别
数学表达:
$$
y^* = \underset{y \in \mathcal{Y}}{\text{argmax}} \cos(f_{\text{image}}(x), f_{\text{text}}(T(y)))
$$
实际应用案例
ImageNet分类
- 传统方法:需要1000类的标注数据训练专用模型
- CLIP方法:直接使用”a photo of a {类别}”模板进行零样本分类
- 结果:CLIP在ImageNet上达到76.2%的准确率,接近专用模型
细粒度分类
- 数据集:Oxford-IIIT Pets(37种宠物狗)
- CLIP表现:无需任何训练,达到93.7%的准确率
- 优势:无需收集和标注昂贵的细粒度数据
动作识别
- 数据集:UCF101(101种人类动作)
- 挑战:动作描述更复杂(如”跳水”、”弹吉他”)
- 解决方案:设计更精细的提示模板
- 结果:达到88.7%的准确率
类别扩展能力分析
CLIP的零样本能力具有很好的可扩展性:
- 新类别:只需提供类别名称,无需重新训练
- 跨语言:支持多种语言的提示文本
- 组合概念:可以理解”红色的汽车”、”在沙滩上的狗”等组合概念
- 抽象概念:可以识别”快乐”、”危险”等抽象属性
提示工程的重要性
实验表明,精心设计的提示模板可以显著提升性能:
- 简单模板:”a photo of a {}” → 基础性能
- 详细模板:”a high quality photo of a {}, taken with a professional camera” → 提升3-5%
- 集成多个模板:使用多个模板的平均特征 → 进一步提升
这种灵活性使得CLIP可以适应各种下游任务,而无需修改模型参数。
实验结果与理论洞见
规模定律(Scaling Laws)
CLIP论文最重要的理论贡献之一是验证了规模定律在多模态学习中的有效性:
发现1:模型大小与性能的关系
- 更大的模型(更多参数)持续带来更好的性能
- ViT-L/14比ResNet-50在多个任务上提升10-15%
- 没有观察到性能饱和,表明还有提升空间
发现2:数据量与性能的关系
- 更多训练数据持续提升性能
- 从1亿到4亿数据,性能提升显著
- 数据多样性比数据量更重要
发现3:计算量与性能的关系
- 更多的计算资源(FLOPs)带来更好的性能
- 性能与计算量的对数呈线性关系
- 符合神经缩放定律(Neural Scaling Laws)
鲁棒性分析
CLIP在鲁棒性测试中表现优异:
对抗攻击鲁棒性
- 传统模型:对轻微扰动敏感,准确率大幅下降
- CLIP:对抗攻击下的性能下降更小
- 原因:自然语言监督提供了更丰富的语义特征
分布偏移鲁棒性
在ImageNet的多个变体数据集上:
- ImageNet-A(对抗性样本):CLIP显著优于传统模型
- ImageNet-R(艺术渲染):CLIP保持较高准确率
- ImageNet-Sketch(素描):CLIP表现稳定
- ImageNet-V2(分布偏移):CLIP下降幅度更小
跨域泛化能力
CLIP在不同领域的表现:
- 医学图像:无需微调,表现良好
- 卫星图像:理解自然语言描述的遥感图像
- 艺术图像:识别艺术风格和内容
效率比较:对比学习 vs 生成式学习
论文证明了一个关键结论:对比学习比生成式学习效率高4倍以上
实验设计:
- 对比学习:预测”哪句话对应这张图”
- 生成式学习:预测”这张图里具体有什么单词”
- 控制变量:相同的数据、模型大小、训练时间
结果:
- 达到相同性能时,对比学习需要4倍少的训练步骤
- 相同训练时间下,对比学习性能显著更高
- 生成式学习收敛更慢,训练不稳定
理论解释:
- 对比学习是判别任务,更容易优化
- 生成式学习需要建模复杂的条件分布
- 对比损失提供了更强的梯度信号
Zero-shot vs Few-shot vs Fine-tuned对比
| 方法 | ImageNet准确率 | 训练数据 | 灵活性 |
|---|---|---|---|
| Zero-shot | 76.2% | 无 | 最高 |
| Few-shot (4-shot) | 79.5% | 每类4张 | 高 |
| Few-shot (16-shot) | 82.5% | 每类16张 | 中 |
| Fine-tuned | 85.4% | 完整训练集 | 低 |
关键洞见:
- Zero-shot竞争力:CLIP的零样本性能接近传统模型的微调性能
- Few-shot高效性:少量样本就能带来显著提升
- 灵活性权衡:性能提升以牺牲灵活性为代价
计算效率分析
| 模型 | 参数量 | 推理速度(图像/秒) | 内存占用 |
|---|---|---|---|
| CLIP-ViT-B/32 | 151M | 1200 | 600MB |
| CLIP-ViT-B/16 | 150M | 800 | 650MB |
| CLIP-ViT-L/14 | 428M | 300 | 1.8GB |
| ResNet-50 | 25M | 1500 | 400MB |
结论:CLIP在保持强大能力的同时,具有合理的计算开销。
面试问题集锦
技术实现细节
Q1: CLIP的对比损失函数具体形式是什么?温度参数τ的作用?
A1: CLIP使用对称的InfoNCE损失:
$$
\begin{aligned}
\mathcal{L}\_{\text{contrastive}} = &-\frac{1}{N} \sum_{i=1}^N \Bigg[ \log \frac{\exp(s_{ii}/\tau)}{\sum_{j=1}^N \exp(s_{ij}/\tau)} \\
&+ \log \frac{\exp(s_{ii}/\tau)}{\sum_{j=1}^N \exp(s_{ji}/\tau)} \Bigg]
\end{aligned}
$$
温度参数τ控制相似度分布的尖锐程度:小τ使分布尖锐,强调困难负样本;大τ使分布平滑,训练更稳定。CLIP将τ设为可学习参数,初始化为0.07。
Q2: 图像编码器和文本编码器为什么采用独立参数而不是共享参数?
A2: 独立参数的设计基于以下考虑:
- 模态差异:图像和文本是异质模态,特征空间不同
- 优化效率:独立编码器可以分别针对模态特点优化
- 灵活性:可以分别更换或升级编码器架构
- 实验验证:论文尝试了共享参数,但性能下降
Q3: 如何处理不同长度的文本输入?
A3: CLIP使用固定长度的处理:
- 最大长度:77个token(包括特殊标记)
- 截断与填充:超长文本截断,短文本填充[PAD]
- 注意力掩码:使用注意力掩码忽略填充位置
- BPE分词:Byte Pair Encoding将文本转换为固定词汇表的token序列
Q4: 训练时的批次构建策略是什么?为什么N×N对比有效?
A4: 批次包含N对图文,构建N×N相似度矩阵:
- 对称对比:同时优化图像→文本和文本→图像的相似度
- 负样本丰富:每个正样本对应N-1个负样本
- 计算效率:矩阵运算高度并行化,GPU友好
- 语义一致性:确保双向语义对齐
与其他模型的比较
Q5: CLIP vs ALIGN: 主要区别是什么?
A5: 主要区别:
- 数据规模:CLIP 4亿对 vs ALIGN 18亿对
- 架构选择:CLIP使用ViT/ResNet,ALIGN使用EfficientNet/BERT
- 训练目标:都是对比学习,但实现细节不同
- 性能:ALIGN在某些任务上略优,但计算成本更高
- 开源程度:CLIP完全开源,ALIGN仅论文
Q6: CLIP vs BLIP: 生成式vs对比式学习的优劣?
A6: 核心区别:
- CLIP(对比式):学习图文匹配,零样本能力强
- BLIP(生成式):学习生成图像描述,理解和生成兼备
- 优劣对比:
- CLIP:零样本迁移更强,训练更高效
- BLIP:生成能力优秀,多任务适应性好
- 实际应用:CLIP适合分类/检索,BLIP适合生成任务
Q7: CLIP vs 传统监督学习模型:零样本迁移的优势和局限?
A7: 优势:
- 无需标注数据:直接使用自然语言监督
- 开放域能力:可以处理任意新概念
- 语义理解:理解丰富语义而非离散标签
- 鲁棒性:对分布偏移更稳健
局限:
- 特定任务性能:在专用任务上可能不如微调模型
- 提示工程依赖:性能受提示模板影响
- 计算成本:推理时需要编码所有候选文本
- 偏见问题:继承训练数据的偏见
理论理解
Q8: 为什么对比学习比生成式学习效率高4倍?
A8: 理论解释:
- 任务难度:对比学习是判别任务,生成式学习是生成任务
- 优化目标:对比损失提供更强的梯度信号
- 收敛速度:对比学习收敛更快更稳定
- 信息利用:对比学习更高效地利用批量负样本
- 实验验证:论文中严格控制变量的对比实验证明了4倍效率优势
Q9: 规模定律(Scaling Laws)在CLIP中如何体现?
A9: 体现在三个维度:
- 模型规模:更大模型持续提升性能,无饱和现象
- 数据规模:更多数据带来线性(对数尺度)性能提升
- 计算规模:性能与计算量呈幂律关系
- 理论意义:验证了多模态学习的缩放定律,指导后续研究
Q10: 为什么自然语言监督比离散标签监督更有优势?
A10: 核心优势:
- 语义丰富性:自然语言包含属性、关系、上下文等丰富信息
- 可扩展性:可以描述无限多概念,不受固定标签集限制
- 人类对齐:使用人类自然表达,更符合认知方式
- 数据可得性:互联网上有海量图文对数据
Q11: CLIP的鲁棒性来源是什么?
A11: 鲁棒性来源:
- 多视角学习:自然语言提供了多个语义视角
- 语义对齐:视觉特征与丰富语义对齐,而非表面纹理
- 数据多样性:4亿对数据覆盖广泛场景和风格
- 对比学习:学习本质语义相似性,而非表面特征
总结与影响
CLIP留下的宝贵遗产
CLIP不仅仅是提出一个新模型,更是开启了一个新的研究范式:
- 范式转移:从”离散标签监督”到”自然语言监督”
- 数据革命:证明互联网规模数据的力量
- 零样本学习:展示了真正的零样本迁移能力
- 多模态对齐:大规模视觉-语言对齐的可行性证明
后续工作与发展
CLIP激发了大量的后续研究:
OpenCLIP
- 开源实现:社区驱动的CLIP复现和改进
- 更多数据:扩展到20亿+图文对
- 更多模型:支持更多架构和规模
- 广泛应用:成为多模态研究的基础模型
CoCa(Contrastive Captioners)
- 结合优势:对比学习 + 生成式学习
- 统一框架:同时学习匹配和生成
- 性能提升:在多个基准上达到SOTA
BLIP-2
- 高效微调:参数高效的多模态适应
- 视觉问答:强大的视觉推理能力
- 通用接口:统一的视觉-语言接口
其他扩展
- 音频-语言:将范式扩展到音频领域
- 视频-语言:处理时序视觉信息
- 多语言:支持多语言文本理解
工业界应用现状
CLIP及其变体已在工业界广泛应用:
- 内容审核:识别不当内容,理解上下文
- 电子商务:商品搜索和推荐,跨模态检索
- 自动驾驶:场景理解,自然语言指令
- 医疗影像:医学图像报告生成
- 创意设计:艺术创作辅助,风格迁移
对未来研究的启示
- 数据优先:高质量、大规模数据是关键
- 对比学习:对比范式在多模态学习中具有优势
- 零样本泛化:开放域能力是AI系统的重要方向
- 多模态统一:向统一的多模态基础模型发展
结语
CLIP论文是多模态学习领域的里程碑工作。它不仅仅是一个技术突破,更是对AI研究范式的深刻反思:真正的智能理解应该基于人类自然的表达方式,而非人工设计的抽象符号。
通过将视觉特征与自然语言语义对齐,CLIP让我们看到了通往通用人工智能的一条可能路径:让机器像人类一样,通过语言来理解和描述世界。
参考文献
- Radford, A., et al. (2021). Learning Transferable Visual Models From Natural Language Supervision. arXiv preprint arXiv:2103.00020.
- Jia, C., et al. (2021). Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision. ICML 2021.
- Li, J., et al. (2022). BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation. ICML 2022.
- Yu, J., et al. (2022). CoCa: Contrastive Captioners are Image-Text Foundation Models. arXiv preprint arXiv:2205.01917.